














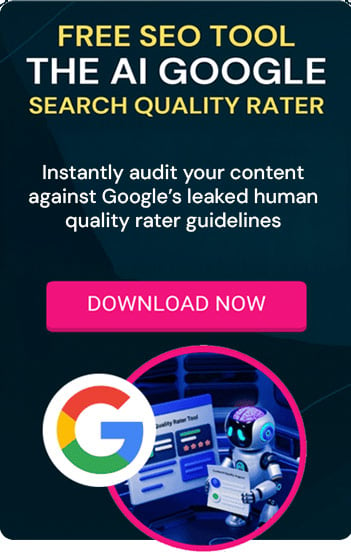















































GPTBot is the new web crawler developed by OpenAI.
It powers AI models such as GPT4 and the future of GPT5.
It is also what gives ChatGPT the ability to write informative AI content that sounds like a human wrote it.
Here’s the problem:
There have been a ton of websites, online publishers and blog owners outraged by the development of GPTBot and AI models.
Why?
AI bots like GPTBot are essentially crawling your content, indexing it and then using it to produce AI-written content.
AI doesn’t add any new value to the article. It’s simply rewriting what’s already out there.
So what can you do about it?
In this blog, we’ll explain exactly what GPTBot is and show you two methods to block it from crawling your website.
What Will I Learn?
What Is GPTBot?
GPTBot is a web crawler developed by OpenAI.
OpenAI uses GPTBot to crawl the internet, index all the data it finds and then use that information to power its AI tools such as ChatGPT.
It’s also what allows those tools to generate AI-based responses to queries or prompts you type in.
The User Agent token for GPTBot is identified as “GPTBot”.
How Does GPTBot Work?
GPTBot operates just like other web crawlers such as:
Think of it like a spider that uses all the links on the internet to discover websites and content online.
As it finds each website, it indexes the content in a large database.
This is exactly how search engines work.

Open AI has developed AI models to understand the information collected by GPTBot and then respond to prompts that people use in tools like ChatGPT.
When GPTBot visits your website, it identifies itself by:
- User agent token: GPTBot
- Full user-agent string: Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; GPTBot/1.0; +https://openai.com/gptbot)
But there are also a few restrictions that Open AI has put on GPTBot when it crawls the internet.
GPTBot should filter out any paywall-restricted content or sources violating OpenAI’s policies. It has also been designed to ignore any specific personally identifiable information.
This is to stop users from stealing content and personal information.
Why GPTBot Raises Concerns?
There is no doubt that GPTBot will make AI models more powerful.
But GPTBot raises a ton of concerns for content publishers and website owners.
Allowing GPTBot to crawl and scrape your website would allow OpenAI to:
- Use your content to train the AI models
- Use your site information to produce AI content
- Add extra server load, potentially affecting website performance
Think about it like this…
If you write an article about how to change a light bulb.
GPTBot can crawl that article and understand the content.
Someone could then prompt ChatGPT to write an article about changing a light bulb.
While the words might be different from your article, the premise and information could be very similar.
Your unique ideas, tools, and strategies could suddenly appear in someone else’s AI-written content.
But that’s not all…
There are also a number of legal and ethical concerns for GPTBot such as:
- Privacy breaches if private or sensitive information is collected
- Infringement of copyright laws if content is used without permission
- Potentially exposing users to outdated or false information
Open AI is committed to addressing these issues.
But the truth is that you have no idea and not a lot of control over what GPTBot is collecting and using from your site.
Major Companies Have Already Blocked GPTBot
 Big publishers are worried.
Big publishers are worried.
So worried, they have taken matters into their own hands.
The New York Times decided to block GPTBot from crawling its site.
The major news company doesn’t want the content they write and publish to be used to train AI models.
It makes sense, right…
The NYT spends millions of dollars every year reporting on the latest news.
GPTBot could potentially:
- Crawl that information in minutes
- Give anyone access to use it in AI-powered tools like ChatGPT
The NYT is so serious they are also considering suing OpenAI for intellectual property rights violations.

There have been a number of other cases where Authors have sued Open AI for intellectual property rights violations.
GPTBot crawled an illegal pirated book site and used the information found there.
If you run a website, you must consider the pros and cons of letting GPTBot crawl your site.
How To Block GPTBot From Crawling Your Site
Want to stop GPT from crawling your site?
There are two ways to do it:
- Block GPTBot with robots.txt
- Block GPTBot Using the .htaccess file
Follow the steps below to block GPTBot from your site.
Method #1 – Block GPTBot With robots.txt
This is the easiest and most common method to stop GPTBot.
But you also rely on the fact that GPTBot will follow the rules you set in your robots.txt file.
That’s not necessarily a problem but just something to keep in mind.
Here’s how to set it up:
Locate your website’s robots.txt file. If it doesn’t exist, create one in the root directory of your website.
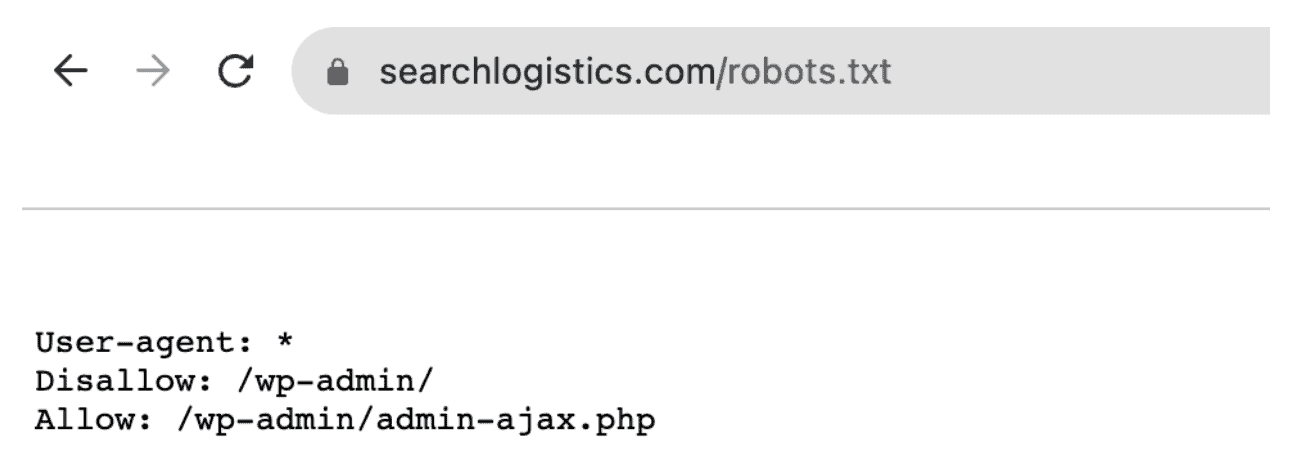
Add the following two lines of code to the robots.txt file:
User-agent: GPTBot
Disallow: /
This will instruct GPTBot not to crawl any part of your website. Open AI has said that GPTBot will follow the rules set in your robots.txt file.
Method #2 – Block GPTBot Using the .htaccess file
Want to take matters into your own hands?
Think of your .htaccess file like a security guard standing at the front gate of your website.
Blocking GPTBot using your .htaccess file will return a “403 Forbidden” response anytime GPTBot tries to access your site.
It requires more technical knowledge but is a sure way to block GPTBot from entering your site.
Here’s how to do it:
Copy and paste the following code into your website .htaccess file:
RewriteEngine on
RewriteCond %{HTTP_USER_AGENT} GPTBot [NC]
RewriteRule .* – [F,L]
That should do the trick!
Wrapping It Up
Now you have a clear idea of what GPTBot is and how to block it (if you want to).
But the big question is…
Should you block GPTBot?
And the answer comes down to your:
- Own preferences
- Business goals
There is no one-size-fits-all answer here.
If you want AI models to understand your content and you are using AI SEO tools for your business, then it might be worth allowing GPTBot to crawl your site.
But if you aren’t going to use AI tools in the future and don’t want new AI models to be trained on your content, then it might be worth blocking GPTBot.
Just remember:
Think carefully about whether you want to block GPTBot or not. It could impact the results of using AI models for your own business in the future.











