




































































What Will I Learn?
What Is Robots.txt?
Robots.txt is a file on your website that tells search engine crawlers which parts of the website you want them to access.
It’s a way of ensuring that search engines like Google only index the pages you want.
For example, you might not want Google to index and display your website login page in the search results.
Adding a directive to your Robots.txt file will stop Googlebot from crawling that page.
No crawl = Noindex.
Note: Robots.txt files don’t prevent web crawlers from crawling your site completely.
It’s up to the web crawler to obey the directions you put in your Robots.txt file.
Common crawlers like Googlebot, Bingbot, Ahrefsbot, Semrush and GPTbot all comply with Robots.txt directions.

What Is Robots.txt Used For?
Robots.txt is used primarily to instruct crawlers about which pages they can and cannot access.
It also prevents server overload from having too many requests from bots.
But that’s not all…
Robots.txt serves a number of purposes:
- Control Over Search Results – While it’s not guaranteed, robots.txt prevents unwanted content like pages, PDFs and media files hosted on your website from being displayed in the SERPs.
- Server Management – Stop your website server from being overloaded by limiting crawler request access.
- Content Crawlabilty – Choose which parts of your site you want to be crawled and indexed.
While Robots.txt is not a “foolproof” method for keeping crawlers off your website – It helps manage the content they crawl and index.
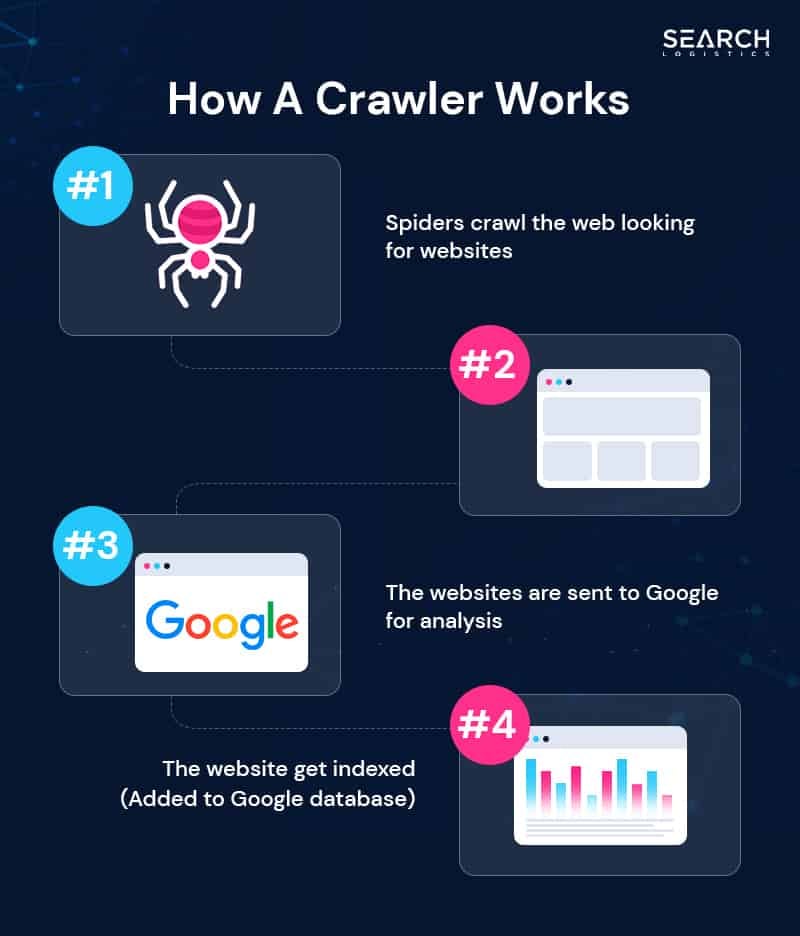
How Does Robots.txt Work?
Robots.txt works by providing instructions to web crawlers, indicating which URLs they are allowed and not allowed to crawl.
Think of Robots.txt like a map to the website pages, documents and media files you want crawled and indexed.
But there are some key things you should know…
Complying with Robots.txt instructions is voluntary.
Reputable search engine crawlers like Googlebot follow these instructions. But that doesn’t mean all online crawlers will.
What does that really mean?
Robots.txt is only a partial solution for blocking crawlers.
For complete control over your website’s visibility, it’s better to use a noindex tag or edit your .htaccess file to block an individual crawler’s IP address.

Is Robots.txt Good For SEO?
Yes, robots.txt is good for SEO when used correctly.
It allows you to guide search engines towards important content while stopping them from accessing unhelpful content or pages you don’t want indexed.
But make sure you pay close attention when editing your Robots.txt.
We’ve had situations where clients have accidentally blocked Google from crawling their website, ultimately removing their entire site from the search results.
How To Find Your Robots.txt File
To find your website’s robots.txt file, simply type in your domain followed by /robots.txt.
It should look like this:
www.yoursite.com/robots.txt
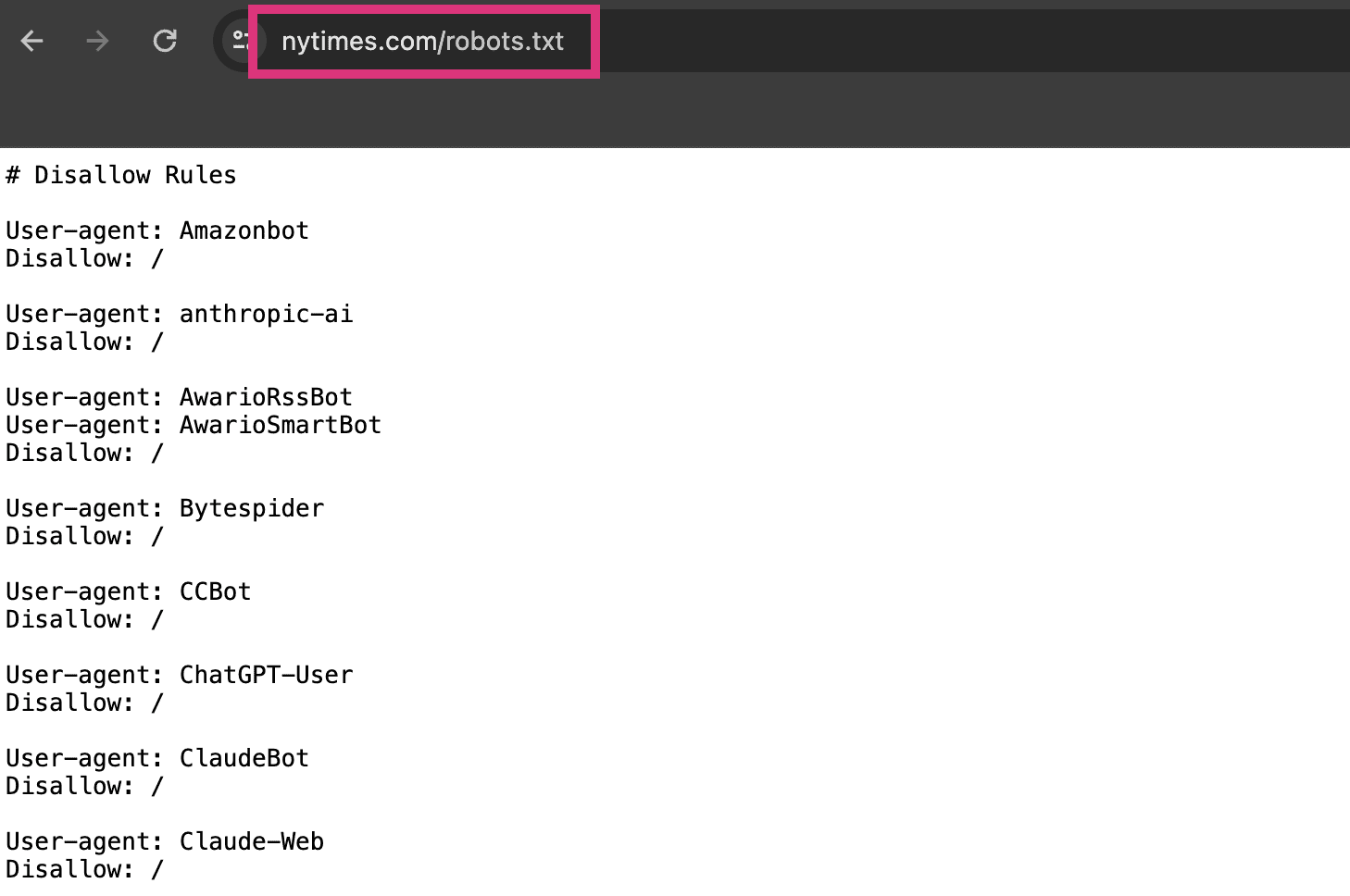
Your Robots.txt file lives at the root of your website.
The method above should make it easy to find.

