





























































Search engines work by crawling billions of web pages using their own web crawlers such as GoogleBot or BingBot.
These are sometimes called search engine crawlers, spiders or bots. A search engine crawler then navigates the web by following links on each new web page that it discovers.
 This is an important piece of knowledge that many new SEOs miss out on.
This is an important piece of knowledge that many new SEOs miss out on.
But understanding how search engines work is paramount!
Why?
Because you need to know how the system works in order to try and leverage it! And this is only becoming more important with AI search platforms like ChatGPT, Gemini, Perplexity, Claude and Grok.
AI platforms now process millions of searches daily. You can’t fix a car’s engine problem without knowing what’s going on under the hood…
… and the same rules apply for all major search engines and AI search tools.
Modern search engine knowledge must include both traditional crawling algorithms and generative engine optimisation (GEO).
With that in mind, I’m going to take you through how search engines work step by step.
Let’s start with the search engine essentials to lay the foundation for a successful SEO career.

What Will I Learn?
How Search Engines Work & Rank Your Pages
Google’s search engine works around crawling and indexing.
We will be looking at these in more detail in a moment.
Search engines use their own search algorithms, so if you appear in the top positions in the search results for one search engine this doesn’t necessarily mean you will for all other search engines.
Some search engines place a heavy focus on web content quality, others user experience and others link building. Understanding what the search engine wants is critical to your success in the search results page.
We’ll look closer at this shortly.
But for now, understand that:
The Google search engine is the pioneer of many techniques you will see in this guide.
- They have 98.98% of the global search engine market.
- AI Overviews now reach over 2 billion users per month (while ChatGPT now has 1 billion weekly active users).
- And “to Google” is an official verb in the English dictionary.
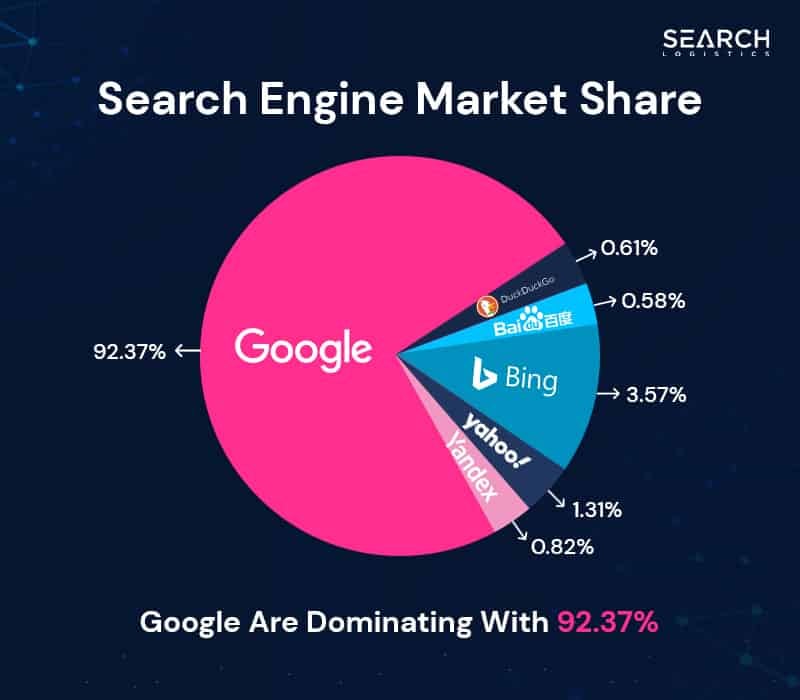
As you can see Google dominates the search engine world. This is true for both traditional search and AI powered search.
But how does the most popular search engine we all know and love function?
It’s actually pretty simple and happens in a 2 stage process-
- Crawling: First Google search “crawls the web” finding new pages to add to their database
- Indexing: Then search results are organised or “indexed” and added to their database
On a basic level, think of it like someone creating a huge library of books.
- Crawling is finding new web books to add to that library.
- Indexing is putting the books you do have in a specific order (like genre or author).
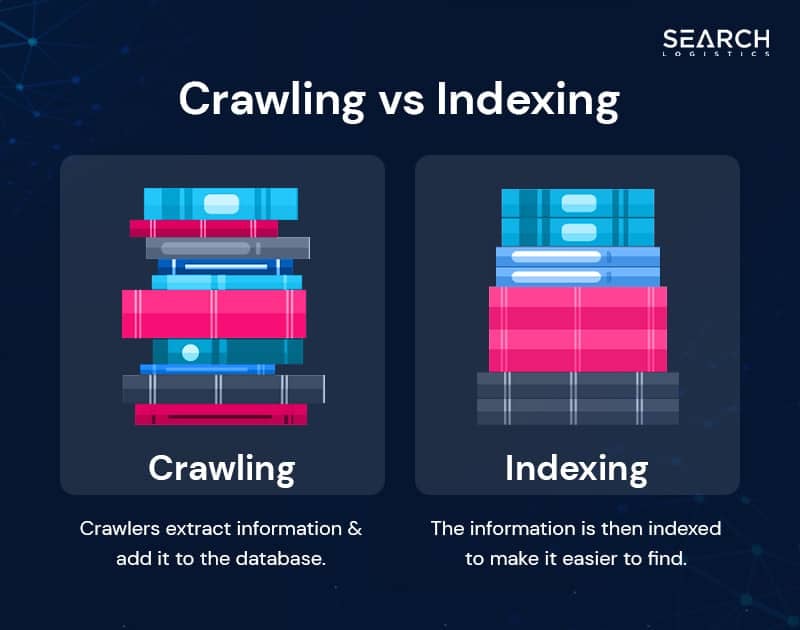
The only difference between a library and Google search – is that Google has billions of books.
What Is Web Crawling?
When you enter a user query in the search engine, you might assume that Google hunts through the entire world wide web in that moment.
What’s really happening is that the web crawler has compiled a huge database of web pages and you are searching that database, NOT the entire world wide web.
The huge database is made up of pre-approved web pages that Google search has checked over and deemed safe for its users.
So you won’t find anything dodgy from the ‘dark web’ for your search query when using Google.
Where it changes is with AI Overviews.
Google’s AI system called Gemini, works in real time to process your search and understand the nuances. It then summarise the top pages related to your search.
This is Google’s search index working with it’s AI model to give you accurate information.
Why Does Google Search Do This?
- It can access this huge database reliably
- It provides a quicker and more user-friendly search experience
- It allows Google to add its own “tags” to these web pages and provide relevant results
The first stage in adding pages to this database is called crawling. Google has “crawlers” (or “spiders”) that it uses to scour the internet.
These web crawlers have 2x jobs-
- Find new web pages to add to search index
- Scrape web content about each web page
I like to think of these web crawlers like spies. They secretly go behind enemy lines to gather relevant information and report back to HQ.
But how do they find web pages, get access and recover that web content? Well, it’s not actually as complex as you might think…
How Does A Web Crawler Work?
All web pages are part of a network called the World Wide Web which is basically like a huge spider web spread all over the world.
The only difference is the world wide web is held together by links (also known as hyperlinks or backlinks).
And search engine crawlers (or spiders) use these links to travel around the web and discover web content!
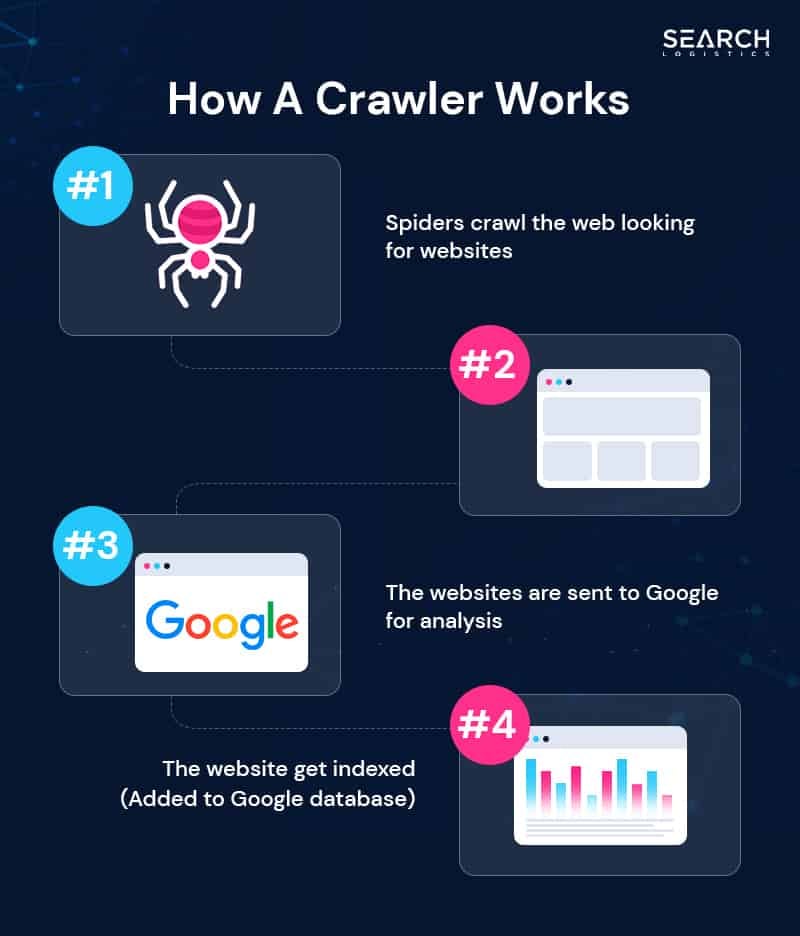
Once web crawlers find a new web page, they start reading all of the web content and code of the page.
In the ideal world, we want the code to be as easy as possible for Google to interpret and understand. Which is where a site owner will perform SEO (search engine optimization).
The crawling process isn’t human-manned and each web crawler works autonomously (using machine learning from the search engine algorithm) to decide whether new pages they find should be added to the Google index or not.
For example:
Crawlers know that sites where you can buy guns and drugs shouldn’t be added to their search index.
But once a web crawler has decided that a page should be added to the search index, it’s time for a site to enter the second stage of the process – indexing.
What Is Indexing?
Once a website has been crawled, it’s time for it to be added to database.
Indexing is where a search engine files away what’s been found and “tags” it.
(It’s a little more complex than that, but tagging works for now).
Think of it in terms of the library example I gave earlier:
If a box of assorted books is dropped off at a library, they will be organised, tagged and placed into their relevant sections-
- Crime
- Fantasy
- Reference
- Biographies

Let’s say you’re interested in learning French verbs.
You might go along to Google and enter the search query “French verb list”.

The search engine will search its search index/database for the indexed pages that match that user query:
(in a matter of seconds)

(Note: To complete more specific research, you can also exclude words from Google search to find exactly what you want quickly).
There is a range of factors that determine why those web pages show up in that order in search results.
These factors vary depending on the search engine you’re using for example Amazon’s ranking factors are very different to Google’s search engine ranking factors (more on that later).
First, just understand that the “indexing” process is fluid and as websites grow/add new content/delete new content – it will be re-crawled and re-indexed to provide relevant results for the search queries.
You can get your web page indexed quicker by submitting your XML sitemap to Google Search Console.
Why Do Some Web Pages Show Up Higher Than Other Pages?
As I briefly mentioned earlier, search engines (also called search platforms) work on search algorithms that determines the order the web pages appear.
That’s a series of equations that are based on different factors that help the computer decide where each piece of content should rank.
With Google search, the simplest way I can explain it is through the concept of voting. In its very basic essence, the more “votes” a website has – the higher it ranks.
Let me explain it in more detail with a live example.
If you wanted to learn how to make money through Fiverr, it’s likely you would enter a user query like this in Google search-

And you’ll find is that lots of web pages show up. But there is one at the top.
That’s my how to make money on Fiverr tutorial:
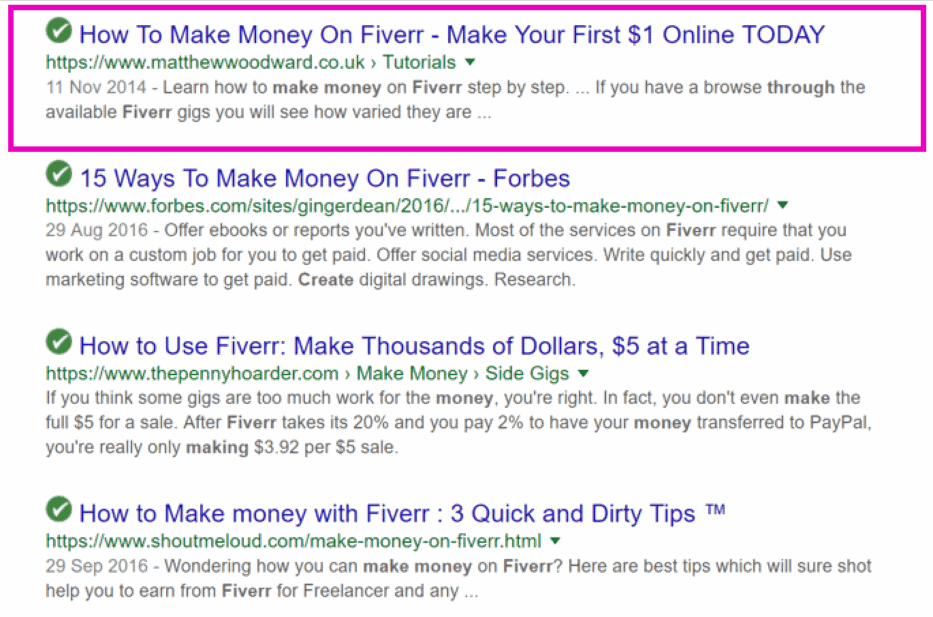
That means of all the web pages that relate to that topic, my site has the “most votes”
But how do web pages get these “votes”?
Well… “Votes” are otherwise known as backlinks (or external links) meaning that when one website links to another website, they are essentially “voting” for it.
For example Niche Pursuits voted for my article when they linked to it-

But that’s not the only vote/backlink that web page has.
It also has votes/backlinks from 83 other web pages-

And for the most part it’s these votes/backlinks that are driving the number #1 position in the search engine results.
BUT!
It’s not quite as simple as that because not all “votes/backlinks” are created equal. The bigger the site and the more well known it is, the more weight their “vote” carries.
If you were to get a link from a big media outlet like The New York Times or The Guardian, it would carry significantly more weight than a link for a brand new unestablished blog.

I’ll show you how all of these pieces together later. But for now:
Remember that in general the more “votes” a web page has, the better and that not all “votes” are created equal.
Stuck in the Google sandbox period? Read my guide to learn how to get out of Google sandbox as quickly as possible.

How Other Search Engines Work And How They Differ
 How do other search engines work in comparison to Google search?
How do other search engines work in comparison to Google search?
Many popular search engines (like Bing) use similar search engine algorithms.
They will crawl and index web pages to use in their search results.
BUT they each have different ranking factors to consider which I will talk about in a minute.
Because there are also other search engines you should be aware of like-
- YouTube
- Amazon
- eBay
- Alibaba
- Etsy
- Quora
These sites all work as popular search engines within themselves but each of these sites has millions of visitors we could tap into.
Which is another reason SEO isn’t dead!
And as long as search engines exist, we will be able to optimise for them.
How Amazon Works
Amazon is one of the world’s leading product search engines!
They offered hundereds of millions of products on their site and it’s internal search algorithm A9, has one main mission:

Whilst this may sound like Google’s philosophy:
Startupbros point out in their guide to ranking on Amazon, they’re slightly different.
- Google says, “What results most accurately answer the user query?”
- Amazon says, “What products is the searcher most likely to buy?””

This is a huge difference because Google’s search engine relies on web crawlers to collect and organise external data.
Whereas Amazon’s search engine relies on internal data that is fully focused on serving their own self-interest..
(Meaning: They want to sell the most products per person)
And Amazon does that by making sure the products you are most likely to buy, show up at the top of its search results.
They use many different factors to figure that out such as-
- How many people have previously bought a product (the conversion rate)
- How well it fits the needs of the buyer (the relevancy)
- The previous actions of the buyer (what they are likely to want to buy this time)
- The overall rating and satisfaction the product provides (how other buyers felt)

This relevant information enables them to show the most buyable product at the top of the search results page.
To give you an example:
If I was to search French learning books:
![]()
That would give me this set of search results.
Can you work out why?
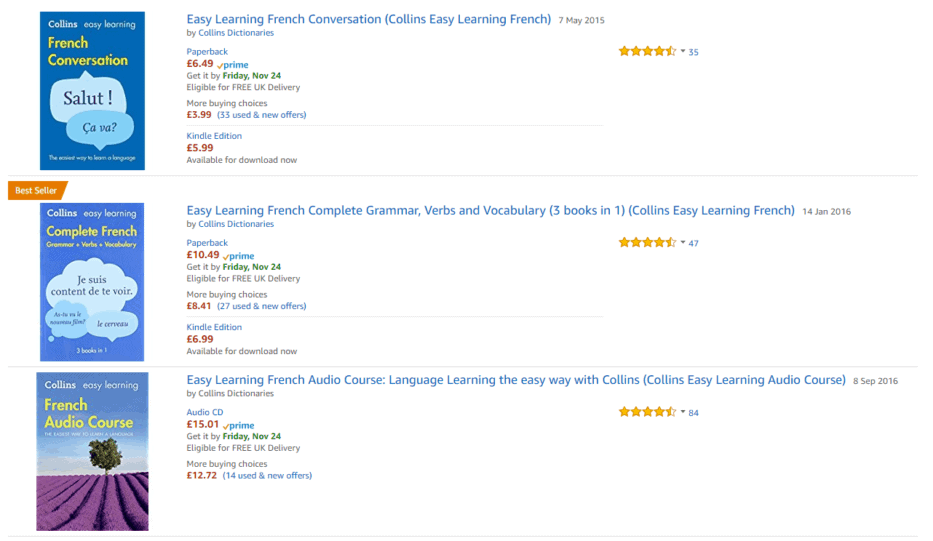
Trying to figure out why is why search engine optimisation exists, because search engines aren’t big on sharing their ranking secrets.
But by observing search results and applying a bit of intelligent thought, we can figure out what is happening-
- The books closely match the keywords I used
- These books are targeted at older learners (I’m logged into my account as an adult)
- They have lots of high ratings (35 to 84 ratings each which is social proof)
- There are tons of positive reviews
- They are affordable (it’s not a product where I’d want to pay $300+)
- They come from a reputable source I’m likely to trust (Collins is a huge UK brand)
If I wanted to buy a French learning book, all of these factors combined would be highly convincing.
And Amazon knows that!
Their search algorithm automatically optimises search results to make sure the perfect product is in front of me when it needs to be.
You can figure out how other search engines work as well just by observing search results and applying intelligent thought.

What Do Search Engines Want?
All search engines have a target goal with the relevant information they provide. They all want to meet the needs of their audience.
But these needs vary for each search engine…
Is to provide you the most accurate answer/solution to your problem.
Whether that’s finding the local news, finding out which nickname Kanye West is now using or planning your wedding.
Is to show you the right product for you to buy.
It finds quality products that meet your needs, backed by a search history of buyer signals and ratings (with fast delivery).
Is to show you the most relevant video content.
Whether that’s a tutorial on brewing coffee or watching gamers play. This keeps user engagement in action and watching ads!
Is to pair you with the right answer to your search terms.
Whether that’s a question that already exists or a question you are asking for the first time.
Trust me when I tell you this:
Taking time to observe and understand what a search engine wants for their users will make your life much easier as an SEO.
Because once you know that, all you have to do is optimise for that!

(If you want to dive deeper into SEO, I recommend you check out my list of SEO books).

Wrapping It Up
If you want to become a successful SEO…
Knowing how search engines work is one of the most important steps. I am going to cover more technical aspects with you soon.
For now let’s quickly recap what you’ve learned:
- Google’s database is created by crawling and indexing web pages
- Crawling is when search engine bots (or spiders) follow links to discover new pages
- Indexing is when Google adds new web content to it’s database and adds topic tags
- Many factors influence how websites appear in Google for search terms, the main one is links
- Each backlink to a web page counts as one “vote” for that page, the more votes the better
- Not all backlinks (votes) are created equal, links from high authority pages count for more
- Understanding a search engine’s goal helps you understand how they work and how to optimize your site
So now you know the basics of how search engines work…
…let’s get our hands dirty by taking a deep dive into Google ranking factors.

Please feel free to ask any search engines dedicated questions you have in the comments below…
Frequently Asked Questions
You Might Also Like




What Are Your Thoughts?
36 Responses








This post is super enlightening! The advancements in search engine technology are fascinating, especially the emphasis on AI and user intent. It’s exciting to think about how these changes will affect our search habits. Can’t wait to see how this evolves further!
Great insights into the evolving landscape of search engines! It’s fascinating to see how AI and machine learning are shaping search algorithms in 2024. I especially appreciate the tips on optimizing content for voice search. Looking forward to implementing some of these strategies!
Glad you enjoyed this post!
Love this deep dive into search engine functionality for 2024! The explanations of advanced algorithms and indexing methods provide a clear picture of how to enhance search engine visibility.
Fantastic post! Your insights and detailed explanations really helped deepen my understanding of this topic. Looking forward to more content like this.
Great job on this post! Your attention to detail and thorough explanations make your blog one of my favorites.
Thanks!
Your article is really fantastic. Thanks for sharing such informative content.
Thank you so much for sharing this Valuable information on SEO. Really good site with amazing piece of content. Keep it up.
Thank you!
Thanks for sharing this insightful post.
You’re welcome!
Very helpful post
Thanks!
thanks for information
Cheers!
can you told me what’s the best link indexer service??
There you go: https://searchlogistics.com/seo/tools/backlink-indexers-test/
very nice and helpfull post thank you
No problem!
very good post very helpful info.
Cheers!
now thats a blog post! thanks Matt , been following for years!
Thanks for sticking with me! What do you think to the new homepage?
thanks for giving this amazing information to us.
Hope you found it useful Kishan
Hi, Your post is really amazing. I am a regular reader of your blog and every time I get something new. This post is also informative for me. I was not aware of a few things which you have explained here.
Thanks Himanshu – glad you continue to get value from coming to my blog.
I just wanted to thank you for giving this information away to those of us just starting out. Also thank you for arranging it in such an easy, step by step manner and you can effectively search on it!
Hey Ellery – no problem at all. Welcome to ‘behind the scenes’ of the online world 🙂
Can you help me personaly, plzzz. I am facing a lots of difficulties i need someone to guide me. I AM REQUESTING YOUOne of your visitors.
You can send any requests for me to review via here – https://searchlogistics.com/contact-me/
Thank u for sharing knowledge
Glad I could help 🙂
Hmmmm just stumbled on this concise and informative content, have more clear understanding on how search engine works. thanks for the write up
No worries, understanding how they work is the first step to ranking your websites on them 🙂